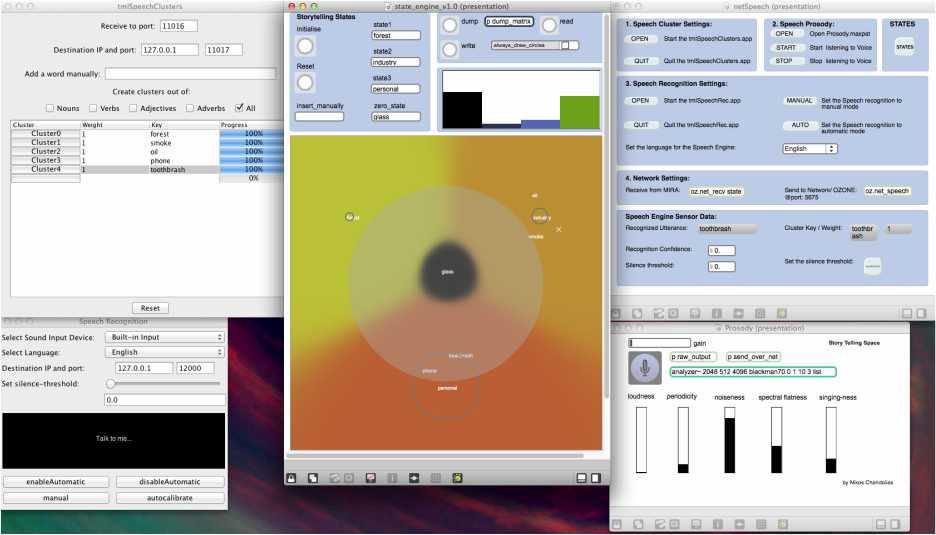
Speech Recognition Engine |
We have create a speech recognition application based in the Google Chrome’s HTML5 speech recognition feature that enables speech recognition for input fields, implemented as a Java Library and creating an interface for our purposes.
The languages that the system can recognize are English, French, Spanish, German and Chinese with- out requiring any training. You can manually set the threshold for the noise level, otherwise you can calibrate the system by pressing the auto-calibrate button. You can perform speech recognition either manually, by pressing the manual button and releasing it once you are done talking, or automatically be enabling the automatic mode. The recognised utterance and the confidence of recognition are being send through Open Sound Control Packets to the network. |
|
The application is based on the Stanford Parser and the Oxford American Writer’s Thesaurus. Once a transcribed utterance is being received or inserted manually the Stanford parser performs natural language processing and through a sophisticated algorithm we create semantic clusters that demonstrate the current notion of the story.
The media artist can also choose from which part-of speech the semantic clusters should be created. Because the application is designed for live performance purposes the media artist might want to change the states of the story by reconfiguring on the spot the way the clusters are created. All the results are being send through Open Sound Control Packets to the network. |
Natural Language Processing System |
Voice Signal Analysis System |
This platform has been created inside the Max/ Msp framework. The Zsa.Descriptors library is intended to provide a set of audio descriptors specially designed to be used in real-time. The system, through the Max/Msp objects , extracts spectral information by performing the necessary FFT transformation. The system on it- self manages the necessary signal windowing, overlapping and adding needed to create a real-time Short Term Fourier Transformation (STFT) analysis aiming to provide an easy way of getting an unique descriptor.
Furthermore, the system provides us ith the loudness of the voice which is measured from the spectral energy, the brightness of the voice which is measured from the spectral centroid and the noisiness which is measured with the Bark-based spectral flatness measure (SFM). All the results are being send through Open Sound Control Packets to the network. |
Story Telling Space System
The documentation below demonstrates the whole story telling system where we can see the previously described applications as well as the state engine that maps the incoming informations to sound and video. The system could be easily used for different types of performances or installations . It is noteworthy, that all the information are available through OSC messages, which means that other people can easily have access to the data.